
We have been dealing with some parts of the data ingestion in Splunk. Now it’s time to put everything we discussed so far into a more helicopter view.
Inputs.conf, indexes.conf and outputs.conf
There are three files on this diagram we did not speak about yet.
inputs.conf: is the file where you define the files/scripts/ports that will do the ingestion of data. For the forwarders this will be mostly scripts and files, for an indexer this will contain the splunk tcp ports 9997 (unencrypted) and 9998 (encrypted).
outputs.conf: is the file where you are outputs, the hosts you will send your data to, are defined. For the forwarders here this will be the splunk tcp ports (9997 and 9998). The indexers if you are data does not need to be forwarded to another SIEM, do not have outputs configured. The output configuration will be a little different in a indexer cluster configuration. But let’s not get ahead of ourselves.
indexes.conf: is the file where all index parameters are defined. Keep in mind that all data that is sent to Splunk need an index. This is the structure that data will be stored in the Splunk platform.
The data ingestion process
- The UF and the heavy forwarders collect the data via configurations in the inputs.conf file. The heavy forwarder is also getting data from (Cloud based) API based technologies.
- The data is sent to a full Splunk instance for parsing and the magic 6 are applied. NOTE: A Heavy Forwarder is full Splunk instance and therefore the data parsing will happen according to it’s props.conf configuration.
Once the data has gone through this step there is no way to change the time stamp extraction or the event breaking. The only solution will be to delete the data and ingest it again with the correct settings. - The last ‘step’ if you can call it that, is that your data can be searched using SPL queries on the Search Head.
On this graph you see that a props.conf can reside on a UF. The only settings that will be applied on a UF are the following:
- INDEXED_EXTRACTIONS: if you are ingesting properly structured data, like a CSV, TSV, JSON field extractions will already happen at the UF level and will be written to disk. Note that this has an impact on the storage needed to index the data.
- EVENT_BREAKER_ENABLE: is a setting where you instruct the UF to already break up the data it reads, into events. The next setting has to be configured as well for this event breaker to work
- EVENT_BREAKER: defines how the UF needs to break the event via a REGEX. In 99% of the cases this REGEX is the same as you would use for the LINE_BREAKER variable on an indexer/heavy forwarder.
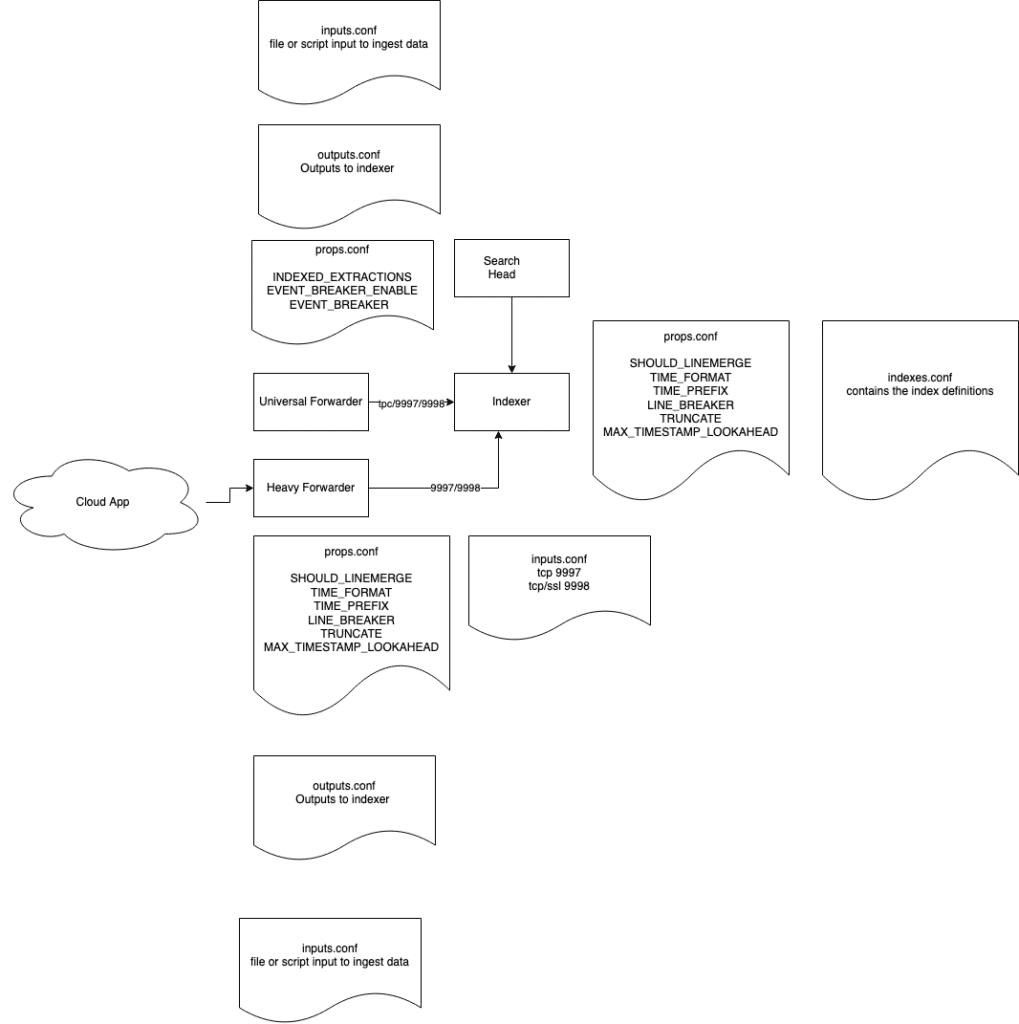
Please note the diagram depicts a very simple straightforward distributed setup. This is simplified for the sake of education. Live production scenarios will contain more nodes and a more complex setup.
This post showcases exceptional research and a deep understanding of the subject matter. The clarity of your writing and the…